
Semantic Exploration and Dense Mapping with Panoramic LiDAR–Camera Fusion
Introduction
This project presents a complete semantic exploration and dense mapping framework that enables a ground robot to autonomously explore, detect, and reconstruct target objects in large unknown environments.
The robot fuses panoramic camera and LiDAR data to build object-level dense semantic maps, integrating viewpoint planning and multi-view fusion to improve mapping completeness and accuracy.
Unlike conventional exploration strategies focused on free-space coverage, our approach explicitly considers semantic targets and object-level observation planning, balancing exploration efficiency and reconstruction quality.

System Overview
The framework consists of four main modules — Mapping, Local Sampler, Global Planner, and Safe-Aggressive Exploration Safe Machine — operating in a closed exploration loop.
The robot incrementally constructs a semantic map, samples informative viewpoints, plans exploration paths, and executes them safely while maintaining consistent mapping and localization.
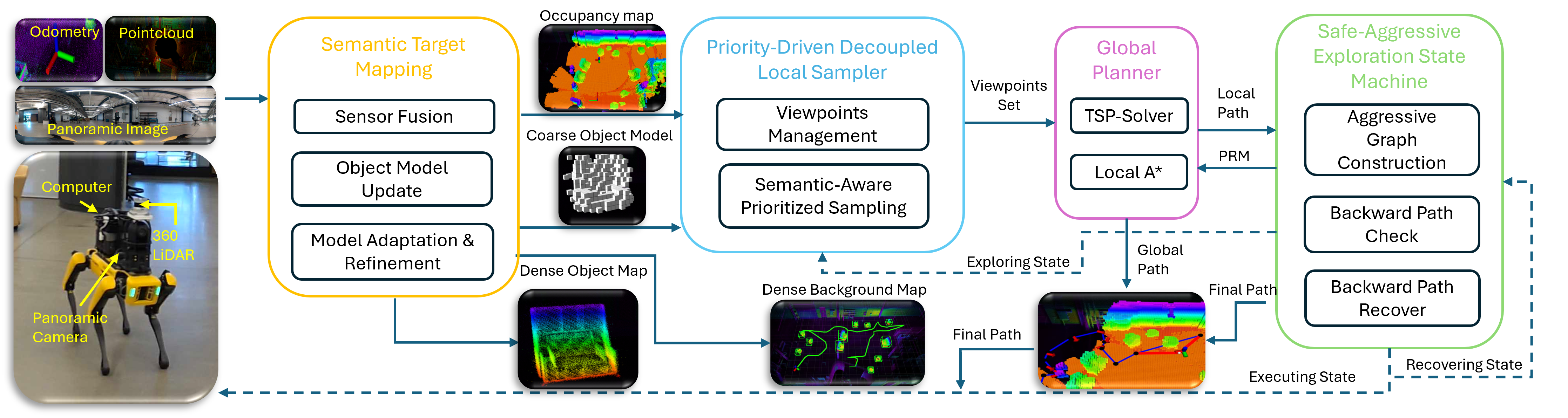
Key Components
- Mapping: Builds a real-time dense voxel map with LiDAR–camera fusion and semantic object reconstruction.
- Local Sampler: Generates viewpoint candidates around exploration frontiers and object surfaces to maximize information gain.
- Global Planner: Selects and sequences viewpoints using an ATSP-based global planner and PRM-based local path search.
- Safe Machine: Monitors collision risks, invalid states, and execution stability to ensure safe and continuous operation.
My Contribution
- LiDAR–Camera Registration: Extrinsic calibration and time-synchronized fusion between an Ouster LiDAR and panoramic camera (C++ / ROS1).
- Semantic Mapping: YOLO + SAM2 segmentation to produce labeled point clouds and voxel-based object maps.
- Coarse-to-Fine Reconstruction: Object model update, merging, and re-centering strategies ensure consistent, complete dense models.
- Multi-View Integration: Fuses observations from different viewpoints to reduce occlusion and sensor noise.
Video 1 – LiDAR–camera registration and fusion demonstration
Benchmark Results
The exploration planner achieves significantly higher efficiency compared to traditional methods by prioritizing regions with semantic value and minimizing redundant motion.

- Exploration time reduced by >40% compared to baseline planners
- Viewpoint coverage improved by ~30% for semantic targets
- Ensured full dense reconstruction in large-scale industrial environments
Real-World Results
The framework was validated in real-world construction and lobby environments.
It successfully reconstructed complex, cluttered scenes with high semantic consistency and sub-centimeter accuracy.
Quantitative evaluation of the reconstructed maps was conducted on two environments. comparing both whole-map and object-level results. Metrics include map completeness, mean distance, and standard deviation of geometric alignment against ground truth.
| Environment | Map Type | Completeness | Mean Dist (m) | Std (m) |
|---|---|---|---|---|
| Construction Site | Whole Map | 99.65% | 0.0227248 | 0.0651594 |
| Object Map | 87.03% | 0.0310901 | 0.0413562 | |
| Lobby | Whole Map | 99.72% | 0.0050834 | 0.0048516 |
| Object Map | 97.22% | 0.0175095 | 0.0231272 |
Table 1 – Statistical evaluation of real-world dense reconstruction results.

Video 2 – Final semantic exploration and mapping demonstration